SSAS: Optimize Dimension attributes, hierarchy, key as integer or uniqueidentifier. Test with 9 database tables with each 1 million records.
This is a project created with the goal in mind to get insight in various options for optimizing a dimension in a SSAS multidimensional cube.
We want to see the difference in performance by using a key based on integer or uniqueidentifier.
We want to see the performance of the cube in following cases: we do not optimize the dimension at all, we only define attribute relationships, we define attribute relationships and hierarchy or we only define a hierarchy. For the cube performance we look at the full processing speed and the query speed.
We have two data warehouse database databases with similar structure and eight simple cubes with just a dimension and a measure.
This is the data-warehouse database structure for the version based on foreign keys which are integers (db name is BigDataKey):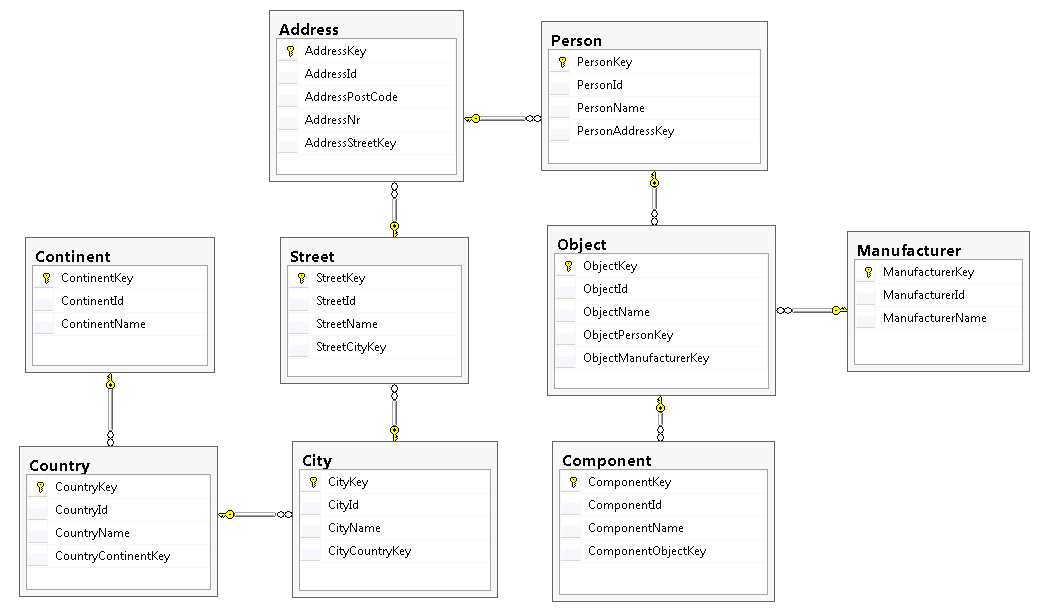
The database structure for the version where the foreign keys are of type uniqueidentifier (db name is BigDataId) is similar to the one above, but for example ObjectPersonKey is called ObjectPersonID and is of type uniqueidentifier. For both versions we have for each entity (as for example Person) both a Key of type integer and a Id of type uniqueidentifier. This has been done because it is possible that the source system uses primary keys of type uniqueidentifier as for example CRM does.
On top of this structure we have a view called AllData which link all tables together via inner joins and has his own key (integer) which is generated on the fly using ROW_NUMBER()
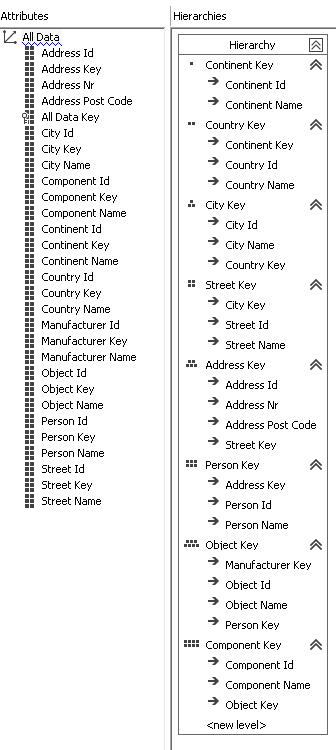
Attribute relationships, we have 8 levels:

Hierarchy:
Test results:
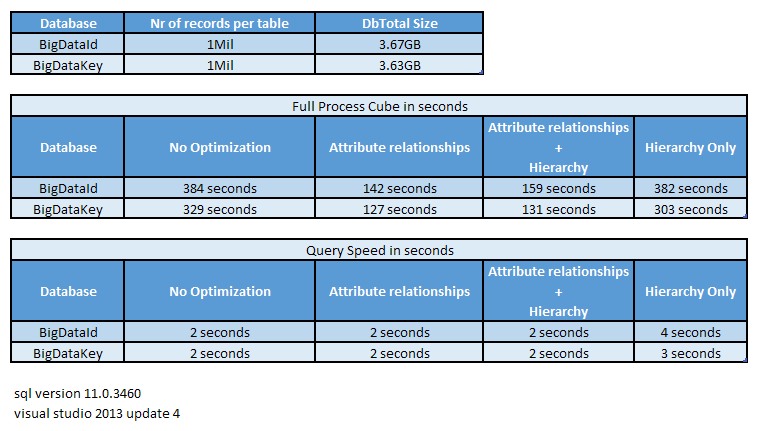
As we can see the database based on foreign keys of type integer is faster, but not by much. The biggest difference is made by defining correct attributes relations, this makes the full processing of the cube 2x times faster. Surprisingly, there is almost no difference in the mdx query speed, but i think this is because my laptop has a lot of memory (16GB) and the cube is quite small and simple with just one dimension and measure. The overhead on creating the hierarchy is not big and i advice to go for it. Before executing a mdx query the cube cache was cleared every time to try to get comparable results. I also noticed that a second time executing a full cube processing can be much faster because the operating system en database server using their caches.
Download the full source for the data-warehouse en ssas cube projects:
Marian Galie Andriescu SSAS Optimize Dimension Test Database and Project Files
Good article on the difference in performance between primary keys of type uniqueidentifier or integer: